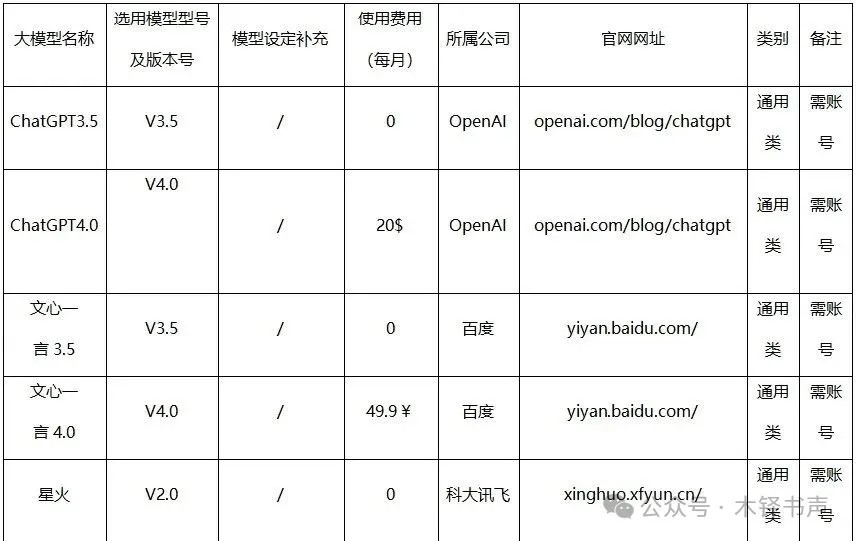
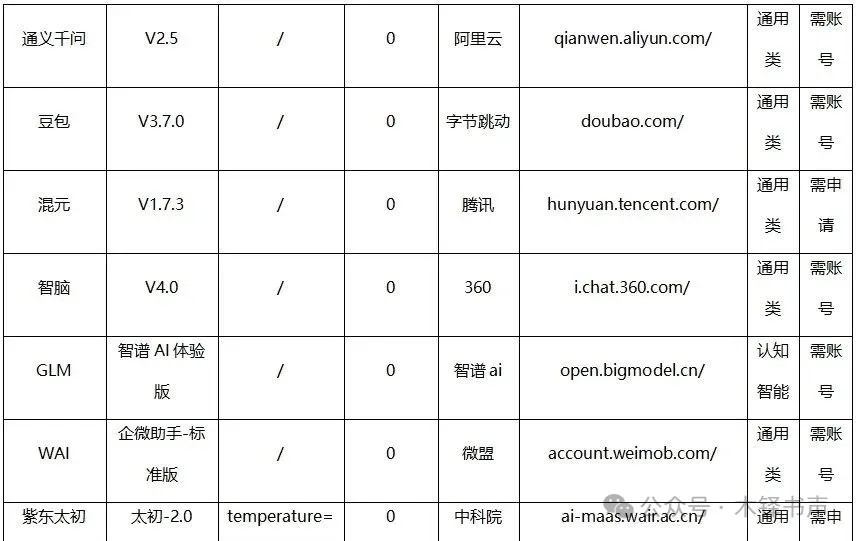
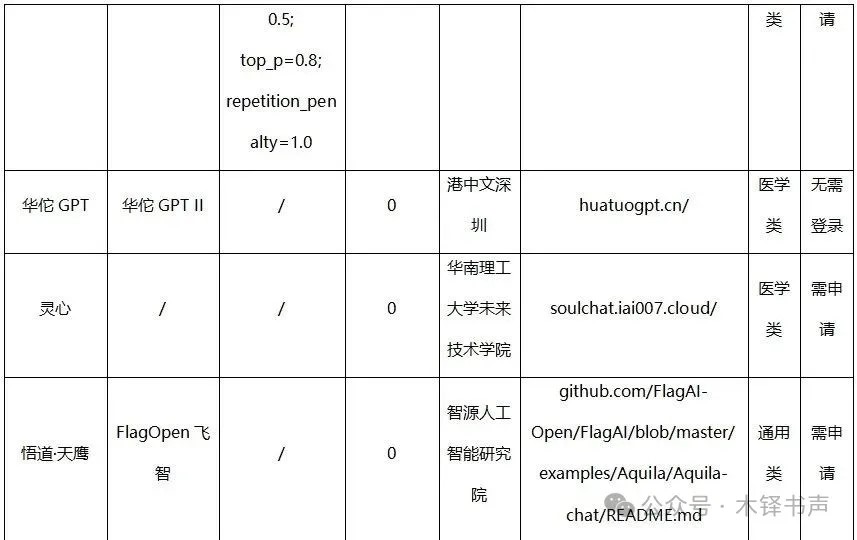
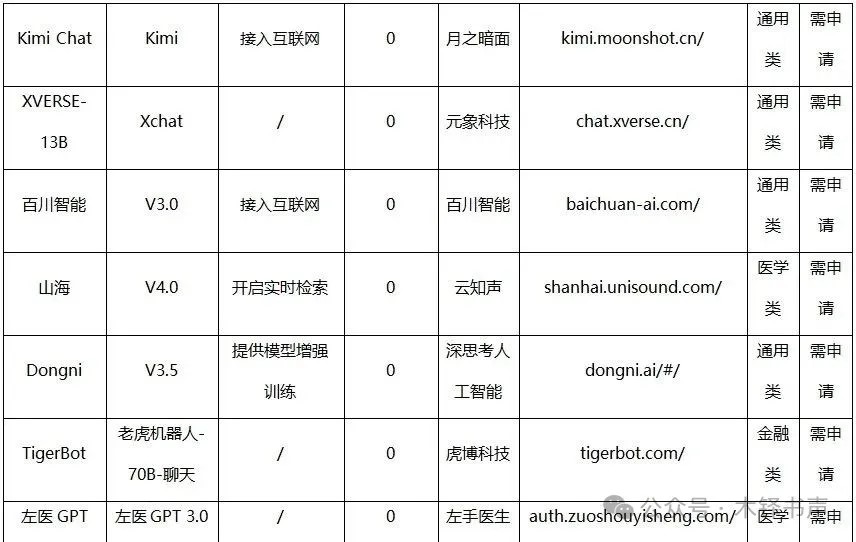
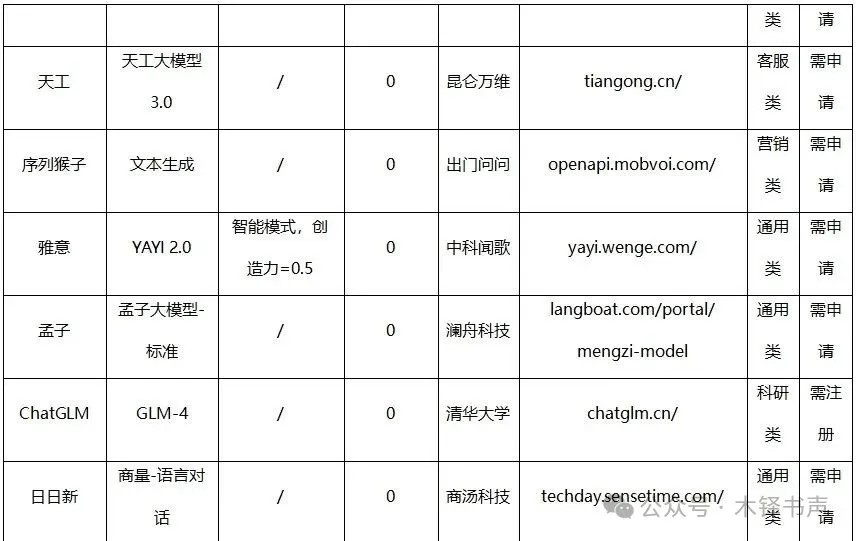
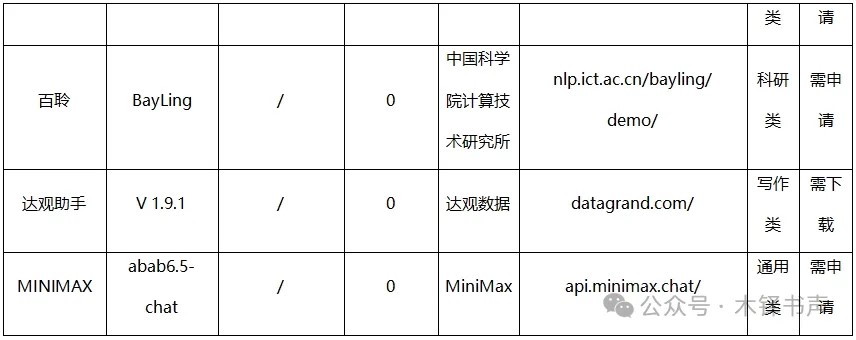
1)现有36个大模型对复杂文本差错的平均编校准确率仅为29.30%,与其对所有测试文本差错的平均准确率35.00%相比,模型的整体编校表现进一步下降。有几个模型编校准确率甚至为0,这表明,在面对复杂、罕见或含有高度专业知识的文本差错时,大模型难以识别其中的差错。
2)部分模型已经具备处理复杂、专业文本的能力。如TechGPT、日日新和ChatGLM,它们对复杂文本差错的编校准确率都超过50.00%;其中,TechGPT在15处复杂文本差错中正确编校10处,编校准确率高达66.67%;另一个突破60.00%编校准确率的模型是日日新,与前文该模型所有测试文本进行编校测试时的表现基本相同。
3)相对原创文本,大模型对已发表和公布的文本有着更为出色的文字编校表现。以XVERSE-13B大模型为代表的部分模型明确指出了该文本的来源期刊,并提供了原文访问接口。这种利用互联网进行搜索的能力显著提升了大模型在处理专业性强、背景知识丰富的文本时的准确性和可靠性。