1.“卷”改为“巷”
2.“茅”改为“芽”
3.“短”改为“毛豆”
例题改编自某稿件的现代文阅读题。笔者检索发现,网上有同样错误的题目还有不少。
文稿中“巷”变“卷”、“芽”变“茅”的错误,用形近致误可以解释。可“毛豆”变“短”未免太过荒诞!是哪个情有独钟的吃货在于坚的那一堆食材中单单挑走了毛豆?
反复思索后,笔者发现了一个突破口:
将左右结构的“短”拆分成“矢”“豆”,与“毛”“豆”二字对比——“豆”与“豆”相同,“矢”与“毛”相似。这样看来,“短”的问题很可能也是一个相似致误的问题。
想要更好地说服自己,我还得解决一个疑问:什么人会在一串食材中把“毛豆”认成“短”?
思考了半天,我才发现自己似乎进入了误区。其实,这很可能是光学字符识别(Optical Character Recognition,简称“OCR”)技术的锅。也就是说,“毛豆”两个字被OCR软件切分成了一个汉字单元。由于OCR字库里没有对应的字,软件便给出了最为形近的“短”作为识别结果。
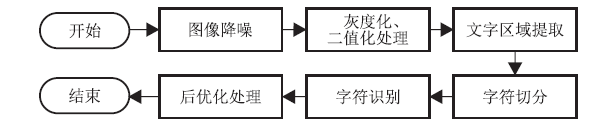
▲OCR 技术流程
截取自王珂、杨芳、姜杉《光学字符识别综述》
由于搜狗输入法对手写字体的识别,也是依托OCR技术。所以,笔者在此使用搜狗输入法手写输入方式给大家做个演示。将毛豆写在一起,看看搜狗输入法会给出什么样的形近字组合。
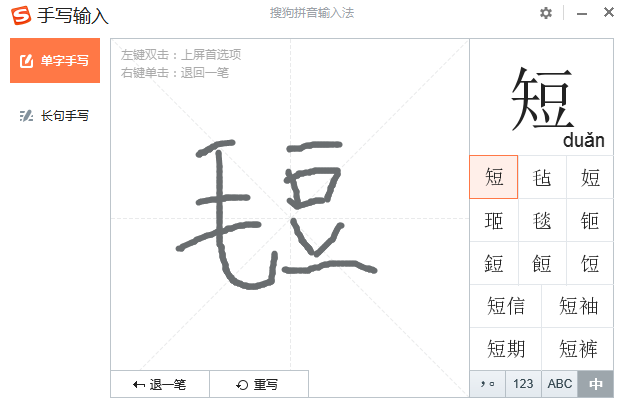
第一次试验,“毛”“豆”二字写得比较瘦长,距离较近,输入法给出的首选字是“短”。
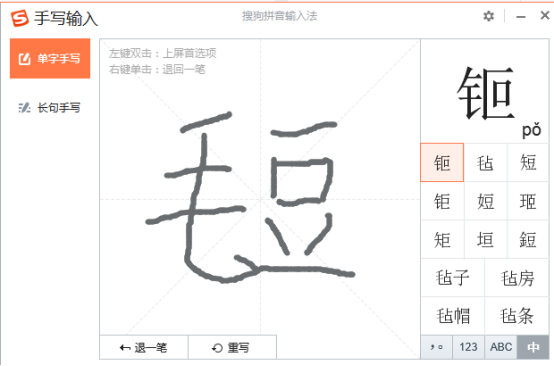
第二次试验,“毛”“豆”二字写得相对肥大,距离较近,输入法给出的首选字是“钷”。
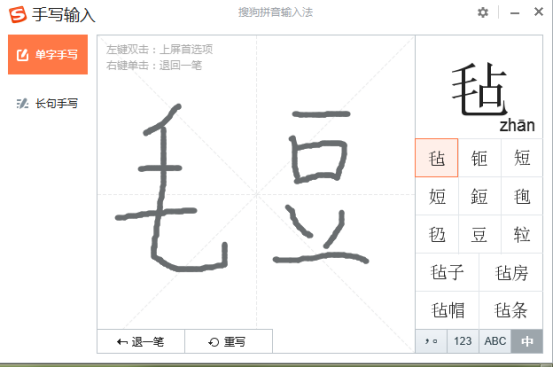
第三次试验,“毛”“豆”二字写得也相对瘦长,距离较远,输入法给出的首选字是“毡”。
三次试验虽然得到了三种不同的结果,但是“无论国际风云如何变幻”,搜狗手写输入法都把“短”排在了前三。虽然“短”的一金两铜相较于“毡”的一金二银地位较弱,但是仍然有较大参考价值。
OCR技术现已成为包括出版业在内的很多行业的主流文字识别技术。用户用OCR技术把通过扫描、摄像等将光学输入方式得到的图书、杂志、发票、证件、车牌等图像文字信息转化为可供计算机识别和处理的文本信息,极大提高了文字存储和加工效率。
现在已有许多作者在组稿时运用OCR技术录入文字资料,或者复制他人用OCR技术整理的文档,所以编辑编校的稿件中与OCR相关的错误越来越多,而且很多错误超出了我们旧的认知范围。
目前,对于编辑来说,收集OCR技术识别的文稿中的各种形近错例并结合OCR工作机理进行分析研究,是十分必要且迫切的任务。
孤木不成林。推定一种新趋势,必然要以足够多的现象为依据。OCR技术已经广为应用,由此带来的形近字——说“形近字符”更确切一些——错误有哪些?下面,笔者结合近来的工作经历,列举三类常见的形近字符错误。
1.此外,朴素观还导出重实质轻修饰、重内客(容)轻形式等观念。
2.他有点傻气,有点采(呆)气,姜亚芳就说他是书采(呆)子。
3.请秀(秃、髡)发,衣胡服,挟弓矢,赍粮饷,为胡人。
4.本品容易受潮,宜放在干燥处,或装在瓶内,但受湖(潮)后效力不变。
5.浓墨叙写相邀(祖逖)事迹,感情激越。
6.雨深一尺春耕利,Et(日)出三竿晓饷迟。
7.fl(自)然而然
8.购(趵)突泉
9.渭城朝雨泪(浥)轻尘,客舍青青柳色新。
渭城朝雨泪(浥)轻尘
10.依中国传统家族文化言,五服之内_(一)般被视为差序格局的里层……
1.黄牛峡:崆岭峡内之峡。东距宜昌市45kin(km)。以长江南岸之黄牛山而得名。
2.A.Ampere(Ampère)和M.Faraday等人发展了唯象理论。
3. Ⅲ(111);111(lll)
4.读秀搜索句:颗粒污染具体分为两类:细颗粒(PM2.5.直径d≤2.Sym)和可吸人粗颗粒(PM10,2.5ymd10p~m)。
原句:颗粒污染具体分为两类:细颗粒(PM2.5,直径d≤2.5μm)和可吸入粗颗粒(PM10,2.5μm<d<10μm)。
原著PDF截图
韩志跃.烟火气体发生剂技术[M].北京:北京理工大学出版社,2020.P78
5.初步核算,全年国内生产总值I31015986亿元,比上年增长2.3%。其中,第一产业增加值7754(77754)亿元,增长3.0%……国民总收入【4】1009151亿元,比上年增长1.9%。全国万元国内生产总值能耗ID】比上年下降0.1%。预计全员劳动生产率【6】为17746(117746)元/人,比上年提高2.5%。(据《中华人民共和国2020年国民经济和社会发展统计公报》截图转换)
《中华人民共和国2020年国民经济和社会发展统计公报》截图
截取自国家统计局官网
1.他们率先在铷原子中创造出了玻色一(-)爱因斯坦冷凝物。玻色一(-)爱因斯坦冷凝物是指一组被冷却的原子……
2.J·K·(J.K.)杰罗姆
3.《左传.襄公二十五年》(《左传·襄公二十五年》)
4.〈〈乡土中国》(《乡土中国》)
5.《皇帝的新衣)(》)
6.外戚中‚更是(“)一表三千里”。
7.费孝通提出了用不同标准来对待和自己关系不同的人的传统社会的差序格局“(“差序格局”),但是局限于……
8.在古代,人们常用晦,(、)望、既望、朔等表示月相的特称来纪日。
9.“道德境界”以现实与理想之间存在着距髙为前提.(。)以主客尚 未(尚未)达到最终的融合为一为前提……
张世英著;江力选编. 我的思想家园[M].北京:
中国三峡出版社,2009.P79截图
正所谓“见怪不怪,其怪自败”,要不为这类形近问题困扰,更好地做好编校工作,就要了解那些由于OCR技术的广泛应用而导致的影响出版质量的形近字符错误新趋势。
4.1 类似“书采子”“45kin”的低级形近错误,会越来越多。
因为以后会有越来越多的作者使用OCR技术进行文稿扫描,网络上可以复制粘贴的扫描文稿也会越来越多,所以约稿时要对作者严格要求,不禁止作者使用OCR技术,但是在扫描后应该认真校对。
4.2 稿件中可以划分在“形近”错误范围内的问题,较过去大大增加。
以前强调的形近错误,基本上都是作者和相关出版人员犯的;以后则会有更多的机器(软件)犯的形近错误,这尤其需要编校人员加以留意。只有最基本的形近字知识储备和形近字校对思维,已不能很好地满足新形势下的稿件编校需求了。
比如上面的“毛豆”问题。又如:他骄做自满,尾巴翘上天了。笔者最先想到的是音近问题,打算把“做”改成了“作”。可是转念一想,“骄作自满”是啥子?结合字形和语境,笔者判断“傲”变“做”,软件识别的形近错误概率要比拼音打字导致的音近错误概率高很多,于是便改“做”为“傲”。
4.3 新的形近字错误,常常给人一种荒诞的感觉,但仔细分析,却又有相似性和相关性。深层次原因,正是OCR技术的工作机理。
比如上面“相邀事迹”的错误出自一篇关于祖逖的文言文阅读理解题。可是通读全文,根本就没有出现“相邀”二字,“相邀事迹”这样的搭配也是看得笔者一头雾水。
没办法,笔者只好拿“相邀”二字与文言文中出现的所有汉字对照,发现字形上与之最相像的是“祖逖”,而且将“相邀”置换成“祖逖”后,句意方面也说得通。笔者感觉这可能是OCR导致的形近错误,于是跟责编要来原稿核查,发现原稿上对应的语句是“浓量叙写相邀事迹,感情激越”。
由此,笔者更加坚定了自己的判断。在具体的语境中,我们不可能将“祖逖”认作“相邀”;可是OCR软件处理时,“祖”“逖”被分别识别,它们单独与“相”“邀”勾连的可能性大大增加,最后被识别成“相邀”也就不足为奇了。
由于OCR扫描文稿中的形似错误比较多,校对者在获取一定成果之后,往往会有一种“满足感”和“疲劳感”,放过一些比较隐蔽的错误。有的文段局部会出现规范字和异体字混合使用的情况,稍有不慎便会漏过错误。比如下面两张图,截取自分布在两页中的一段相连的文字。上一页的5个“查”全是规范字,而到了下一页,突然“字风一转”,4个“査”全是异体字。编校时稍有麻痹大意,便会让这4只猹溜过去——出版的田野里有多少瓜够这些家伙糟蹋?

简单来说,OCR就是计算机以“他”的思维认字。这与我们的认字方式有相似,也有不同。我们要做好编校工作,就要知道计算机与人认字的不同之处。
以上是笔者就OCR技术的应用带来的形近字符错误新趋势所谈的一点浅见。最后,本着“有福同享,有难同当”的“二同”精神,给大家留二道曾经让我倍感折磨的题目吧。
1.可以有各种形式:读书小组、希望小组(中产生组成)、游艺小组(制模、棋类、牌类、环类、拓扑类)、数学陈列室等。
2.我到Texas Alam大学读书后不久就己和Jenny闹翻了。毕业前一天,她突然约我晩上到学校运动场见面……
(1)王珂,杨芳,姜杉.光学字符识别综述[J].计算机应用研究.2020,37(S2).
(2)郇政永.基于OCR的中文文本校对研究[D].北京:北方工业大学,2011.
(3)哔哩哔哩网站:搜狗百度争夺的手写输入法,背后是怎样的基本原理?(黑科技老K)[DB/OL]. (2019-03-21).
https://www.bilibili.com/video/BV1xb411J7qc?spm_id_from=333.337.search-card.all.click
作者 | 杨威威 江苏凤凰教育出版社编辑
编辑 | 夏国强